

Internet es un mundo en constante cambio pero la mayoría de páginas web dejan un rastro que podemos consultar con el tiempo. Las páginas web aparecen, evolucionan y desaparecen constantemente.
Sin embargo, existe una manera de viajar al pasado y ver cómo eran los sitios web hace años, incluso aquellos que ya no existen.
La Máquina del Tiempo de Internet: Wayback Machine
La herramienta más popular y completa para ver páginas web antiguas es sin duda la Wayback Machine del Internet Archive. Este proyecto ha estado archivando la web desde 1996 y cuenta con billones de páginas web guardadas.
¿Cómo usar correctamente Archive.org?
- Puedes visitar la web: https://web.archive.org
- Ingresa la URL del sitio web que quieres consultar en el buscador (puedes intentar con tanto http como https)
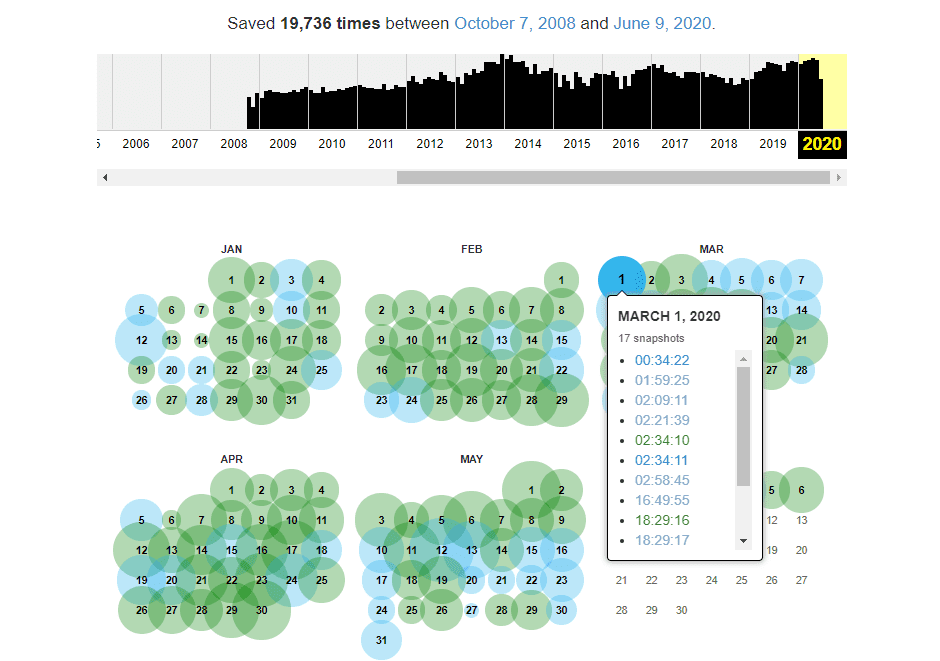
- La Wayback Machine te mostrará un gráfico que indica cuántas veces se guardaron copias de ese sitio web a lo largo de los años
- Al hacer clic en un año específico dentro del gráfico, podrás acceder a copias individuales del sitio mediante un calendario
- Selecciona una fecha concreta para ver cómo era exactamente el sitio web en ese momento:
¿Qué significan los colores celeste y verde en Archive.org?
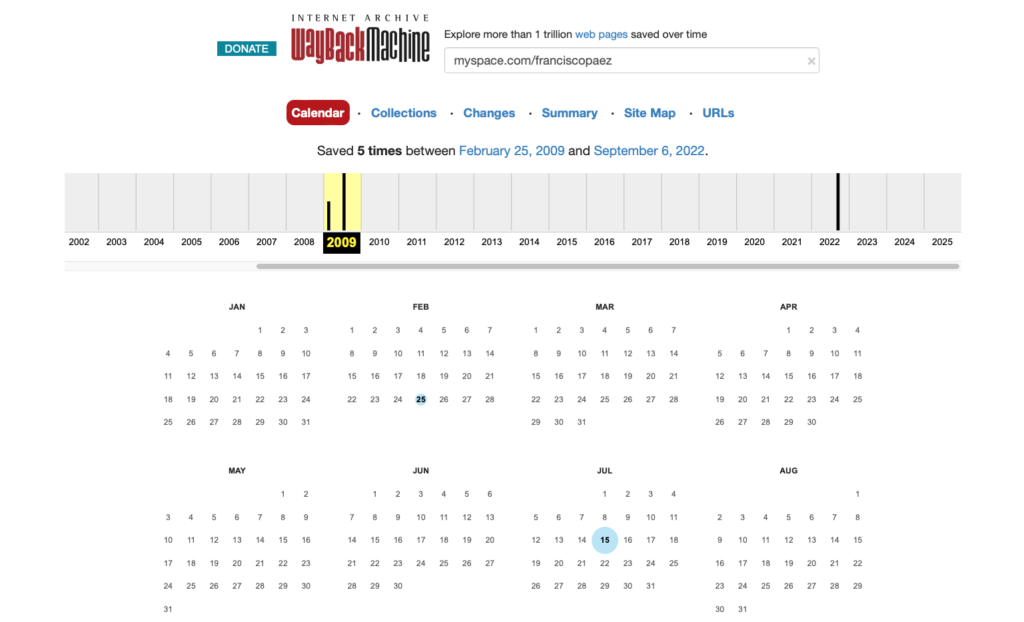
Cuando encuentras una fecha con un circulo azul o celeste, significa que existe un registro grabado, esto no garantiza que esté correctamente registrado, pero habrá una gran posibilidad. Al hacer clic, podrás ver diferentes «horas» en las que se grabó la versión de esa URL , generalmente encontrarás grabada la página INICIO, por lo que puedes darle clic a cualquiera de las horas disponibles.
Pero cuando encuentres un circulo verde oliva, será mejor que NO le des clic, eso significa usualmente que el usuario entonces, colocó un codigo 301 o 302 para hacer redireccion forzada, esto puede ponerte en riesgo, ya que muchas veces las páginas web antiguas fueron atacadas por virus y por hackers que lograron instalar estas redirecciones maliciosas, por lo que NO te recomiendo visitar estos archivos de web.

Otras herramientas para ver páginas web antiguas
Aunque Wayback Machine es la opción más conocida, existen otras alternativas:
Archive.today
Archive.today es otra herramienta que permite guardar y consultar capturas de páginas web. A diferencia de Wayback Machine, Archive.today captura la página completa, incluyendo elementos dinámicos.
Google Cache
Google guarda versiones en caché de las páginas web que indexa. Para acceder:
- Busca la página en Google
- Haz clic en la flecha pequeña junto a la URL en los resultados
- Selecciona «En caché»
Este método solo permite ver versiones relativamente recientes.
Bibliotecas nacionales
Algunos países tienen iniciativas para preservar su patrimonio digital:
- La Biblioteca Nacional de España tiene su archivo web
- La Library of Congress de Estados Unidos también archiva sitios web de relevancia histórica
Limitaciones al consultar páginas web antiguas
Cuando utilizas herramientas de archivo web para consultar versiones antiguas de sitios, es fundamental comprender sus limitaciones para tener expectativas realistas sobre lo que podrás encontrar y qué tan completa será la experiencia.
No Todas las Páginas Web Están Archivadas, Sobre Todo de los Países Hispanohablantes
La verdad simplemente no todas las páginas han sido guardadas. Los servicios de archivo web como Wayback Machine funcionan mediante robots que rastrean la web, pero nadie conoce los criterios que utilizan para ello. Es una iniciativa privada, sin fines de lucro que depende de donaciones y a decir verdad, recaudan muy poco comparado con lo que gastan en millones de hosting. Su prioridad son clientes que utilizan esos archivos históricos para fines de colección de data, pero nadie sabe muy bien qué criterios toman en cuenta.
Para América Latina los archivos son aún más limitados. Los servicios de archivo web tienen un sesgo histórico hacia contenido en inglés y sitios de Estados Unidos y Europa. Esto significa que si estás buscando versiones antiguas de sitios web guatemaltecos, salvadoreños, hondureños o de otros países latinoamericanos, las probabilidades de encontrar archivos completos y frecuentes son significativamente menores.
Los sitios web más pequeños, locales o regionales tienen menos probabilidad de haber sido archivados que grandes portales internacionales. Una empresa mediana en Ciudad de Guatemala que tuvo su primer sitio web en 2008 probablemente tenga pocas o ninguna captura en los archivos web, mientras que un sitio de noticias internacional del mismo período probablemente tenga cientos de capturas.
Además, la frecuencia de archivo también varía enormemente. Un sitio puede tener una captura de 2010 y la siguiente de 2015, perdiendo completamente todos los cambios que ocurrieron en ese período de cinco años. Esto hace difícil trazar una historia completa de la evolución de un sitio web.
Para empresarios y emprendedores latinoamericanos, esto significa que no deben confiar únicamente en servicios de archivo web para preservar su historia digital. Es recomendable mantener capturas de pantalla propias, respaldos de código y documentación de cambios importantes en sus sitios web.
Algunos Elementos Como Scripts, Formularios o Contenido Dinámico Pueden No Funcionar
Los servicios de archivo web guardan principalmente el código HTML estático de las páginas, pero tienen dificultades significativas con elementos interactivos y dinámicos que dependen de JavaScript, bases de datos o servicios externos.
Scripts y JavaScript: Muchos scripts no funcionarán en versiones archivadas porque dependen de archivos externos que pueden no haber sido archivados simultáneamente, o porque hacen llamadas a APIs y servicios que ya no existen. Esto significa que funcionalidades como menús desplegables, galerías de imágenes interactivas, mapas integrados, calculadoras o cualquier elemento que requiera ejecución de código del lado del cliente probablemente no funcione o funcione parcialmente.
Formularios: Los formularios de contacto, búsqueda interna del sitio, carrito de compras o cualquier elemento que requiera envío de datos a un servidor no funcionarán. Los archivos web solo capturan la apariencia visual del formulario, no la funcionalidad backend que procesa la información. Esto puede ser frustrante si intentas entender cómo funcionaba un proceso de compra o registro en versiones antiguas de un sitio.
Contenido Dinámico: Elementos que se cargan dinámicamente después de que la página inicial se muestra (mediante AJAX, por ejemplo) frecuentemente no aparecen en las versiones archivadas. Esto incluye comentarios que se cargan al desplazarse, productos recomendados que aparecen según el comportamiento del usuario, o contenido personalizado basado en la ubicación geográfica del visitante.
Aplicaciones Web Complejas: Plataformas web complejas como redes sociales, herramientas SaaS o aplicaciones de gestión empresarial rara vez funcionan correctamente en archivos web. Puedes ver la interfaz visual, pero la funcionalidad real estará completamente rota.
Para diseñadores y desarrolladores web que buscan estudiar cómo funcionaban ciertos elementos interactivos en el pasado, esta limitación significa que los archivos web son útiles principalmente para análisis visual y estructural, no para comprender completamente la experiencia de usuario interactiva.
Sitios Protegidos con Contraseña o que Bloquean Robots No Suelen Estar Archivados
Los servicios de archivo web respetan las directivas técnicas que los propietarios de sitios establecen para controlar cómo los robots rastreadores acceden a sus páginas. Esto significa que grandes porciones de la web nunca llegan a ser archivadas por razones técnicas o de privacidad.
Sitios Protegidos con Contraseña: Cualquier contenido que requiera iniciar sesión o ingresar una contraseña para acceder no será archivado. Esto incluye áreas de miembros, intranets corporativas, plataformas educativas privadas, foros cerrados y secciones premium de sitios web. Solo el contenido público y accesible sin autenticación tiene posibilidad de ser archivado.
Archivos robots.txt Restrictivos: Muchos sitios web incluyen un archivo llamado robots.txt que indica a los rastreadores web qué páginas pueden o no pueden indexar. Los servicios de archivo web respetan estas instrucciones. Si un sitio bloqueó el acceso a rastreadores (ya sea intencionalmente o por error de configuración), esas páginas no habrán sido archivadas.
Directivas Noindex: Las páginas pueden incluir metaetiquetas que específicamente instruyen a los robots a no indexar cierto contenido. Los servicios de archivo web generalmente respetan estas instrucciones, lo que significa que páginas con estas directivas no aparecerán en los archivos históricos.
Bloqueo por Dirección IP: Algunos sitios web bloquean activamente rangos de direcciones IP conocidos por pertenecer a servicios de archivo web o rastreadores. Esto puede ser por razones de seguridad, para reducir carga en el servidor o para proteger contenido propietario.
Contenido Geobloqueado: Sitios que restringen acceso basándose en ubicación geográfica pueden no estar disponibles para archivadores que operan desde ciertas regiones. Esto es común en servicios de streaming, sitios de noticias regionales o plataformas de comercio con restricciones territoriales.
Para empresas que operan sitios web con áreas privadas o restringidas, esto significa que esas secciones no tendrán respaldo histórico en archivos públicos. Es fundamental mantener respaldos propios si la preservación de ese contenido es importante para tu organización.
Las Imágenes y Archivos Multimedia a Veces Se Pierden
Uno de los aspectos más frustrantes al consultar versiones archivadas de sitios web es encontrar páginas donde el texto está completo pero las imágenes no cargan, los videos no se reproducen o archivos descargables ya no están disponibles.
Imágenes Faltantes: Las imágenes a menudo se pierden en archivos web por varias razones. Pueden haber estado alojadas en servidores externos que ya no existen, pueden no haberse archivado al mismo tiempo que la página principal, o pueden haberse archivado en una fecha diferente creando inconsistencias. Es común ver páginas antiguas con cuadros vacíos donde deberían aparecer fotografías, gráficos o logotipos.
Videos y Contenido Flash: El contenido en Flash, que fue extremadamente popular hasta mediados de los 2010s, prácticamente nunca funciona en archivos web modernos porque los navegadores actuales no soportan Flash. Videos embebidos de plataformas como YouTube o Vimeo típicamente no se reproducen porque los archivos web guardan solo el código de inserción, no el video en sí, y los enlaces a los videos originales pueden estar rotos.
Archivos PDF y Documentos Descargables: Mientras que algunos archivos PDF se archivan correctamente, muchos se pierden, especialmente si estaban alojados en subdominios diferentes o servidores de archivos separados. Manuales, catálogos, reportes y otros documentos descargables frecuentemente no están disponibles en versiones archivadas de sitios.
Audio y Podcasts: Contenido de audio, especialmente de sitios de podcasts o estaciones de radio, rara vez se archiva correctamente. Los archivos de audio son grandes y no siempre se capturan cuando se archiva una página web.
Imágenes de Fondo CSS: Las imágenes definidas en hojas de estilo CSS pueden perderse porque los archivadores a veces no siguen todas las referencias a recursos externos en archivos CSS. Esto puede resultar en páginas que se ven visualmente rotas o incompletas.
Contenido Dinámico de Redes Sociales: Widgets de redes sociales, feeds de Instagram, timelines de Twitter integrados y contenido similar que se carga dinámicamente desde plataformas externas nunca funcionan en versiones archivadas porque dependen de servicios en tiempo real que ya no responden de la misma manera.
Para diseñadores web y especialistas en marketing digital, esta limitación significa que al analizar diseños antiguos o campañas pasadas a través de archivos web, deben ser conscientes de que la experiencia visual puede estar incompleta. Las decisiones sobre diseño, jerarquía visual o estrategia de contenido multimedia pueden ser difíciles de evaluar completamente sin acceso a todos los elementos visuales originales.
¿Por qué es útil consultar páginas web antiguas?
Poder acceder a versiones antiguas de sitios web puede ser útil para:
- Investigación histórica
- Recuperar información que ya no está disponible
- Verificar cambios en políticas o términos de servicio
- Comprobar declaraciones hechas en el pasado
- Nostalgia por diseños web de otras épocas
La próxima vez que necesites encontrar información de un sitio web que ha cambiado o desaparecido, recuerda que existe una manera de viajar en el tiempo digital.
Recomendaciones finales:
Si tu empresa tiene un sitio web activo y valoras tu historia digital, considera implementar tu propio sistema de respaldo que capture no solo el código HTML, sino también todos los recursos asociados: imágenes, videos, archivos descargables, hojas de estilo y scripts.
Esto te garantizará tener acceso completo a versiones históricas de tu presencia web sin depender de servicios externos que tienen estas limitaciones inherentes.



